Analisando dados do Tesouro Direto com R
O caso de hoje é uma análise de impacto do cenário pandêmico e político no mercado de renda fixa brasileiro utilizando os dados do sistema oficial do Tesouro Direto (TD).
Para isso, utilizaremos a linguagem R tanto para extrair, tratar e gerar a visualização final. No decorrer do artigo, irei detalhar todo o código utilizado, para que no futuro você possa gerar suas próprias análises de títulos públicos com os dados do Tesouro Direto e a linguagem R.
Aqui cabe um adendo importante, para a extração dos dados do TD eu utilizei o pacote GetTDData produzido pelo Professor da UFRGS Marcelo S. Perlin. Ele também produziu outros pacotes relevantes para a análise de finanças quantitativas e, caso tenha interesse no assunto, eu recomendo muito que depois vasculhe os demais pacotes e conteúdos produzidos pelo professor.
Objetivo Final
Esta é a visualização final que iremos recriar no decorrer do artigo, nela temos as taxas de compra de títulos públicos indexadas à inflação (IPCA), as famosas NTN-B, de diferentes vencimentos entre o período de 08/2019 e 05/2020. Através dela, observamos o impacto do atual cenário pandêmico nas NTN-Bs, onde destaco o início do stress ocasionado pelo COVID19 em março e, também, o stress político e institucional gerado pela saída de Sérgio Moro do Ministério da Justiça em abril.
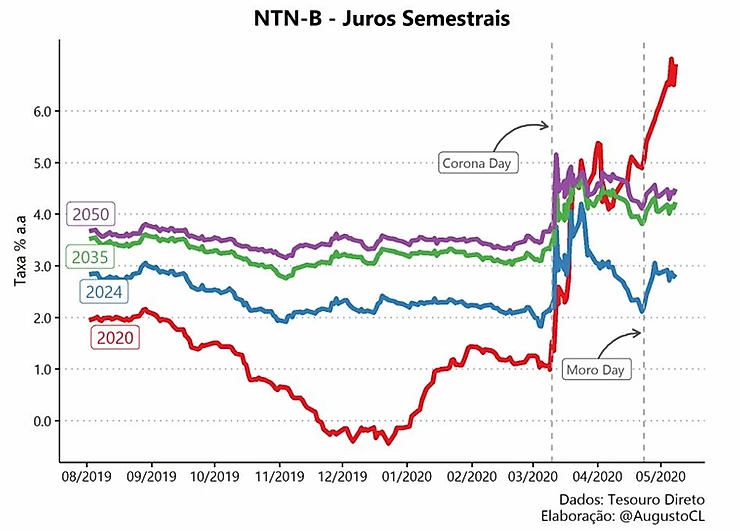
Para aqueles que não possuem familiaridade com títulos públicos, uma rápida intuição para a interpretação das taxas seria a seguinte: quanto maior o risco de default (calote) de um país, maior a taxa de juro exigida pelo mercado para que justifique o investimento naquele título.
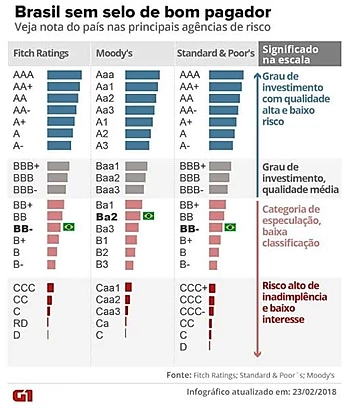
Um exemplo claro deste fundamento são as notas de investimento (rating de crédito) que agências de crédito como Fitch Ratings, Moody's e Standard & Poor's fornecem para cada país, após analisarem o cenário macroeconômico, político e da dívida pública, por exemplo. A título de curiosidade, segue uma visualização do G1 que explicita as diferentes classificações de ratings e seus significados. A visualização é de 2018, quando o Brasil perdeu o grau de investimento, mas mesmo defasada é extremamente útil para fortalecer o entendimento do risco-país.
Enfim, vamos ao código.
1. Instalando pacotes e dependências
Utilizaremos os seguintes pacotes:
· Tidyverse: carrega um conjunto de pacotes utilizados em todo o workflow de datascience no R. Para o nosso caso, utilizaremos os pacotes de manipulação dos dados e geração de gráficos.
· ggthemes: carrega diferentes temas de gráficos para customizarmos nossa visualização.
· GetTDData: pacote responsável pela extração dos dados do Tesouro Direto (TD).
· extrafont: carrega um conjunto de fontes disponíveis para a customização da visualização.
· ggrepel: pacote que ajusta os rótulos dos dados automaticamente para que nenhum rótulo sobreponha outro rótulo.
Caso você não possua algum deles já instalados em sua máquina, será necessário instalar os pacotes faltantes da seguinte forma:

Em seguida, carregamos todos os pacotes e selecionamos a fonte que será utilizada para o nosso gráfico final (Lembrando que a fonte pode ser alterada para qualquer outra de sua escolha).

A função font_import() faz o download de um conjunto de fontes, a função loadfonts(device= “win”) carrega as fontes baixadas para estarem disponíveis no R e o comando custom_font
Dica: o comando fonts() apresenta no terminal o nome de todas as fontes carregadas pelos comandos anteriores.
2. Carregando os dados do Tesouro Direto

Após o carregamento dos pacotes, a função download.TD.data() efetua o download do histórico do sistema oficial do Tesouro e salva todos os arquivos dentro de uma pasta chamada “TD Files”. Em seguida, a função read.TD.files() procura a pasta “TD Files” dentro do seu diretório atual e lê todos os arquivos dentro dela, de acordo com o argumento buscado “NTN-B”.
Dicas:
(i) Para consultar seu diretório atual, execute o comando getwd() e, para selecionar o diretório de sua escolha, digite o atalho CTRL + SHIFT + H.
(ii) Para a seleção de múltiplos títulos é necessário inserir um vetor com os títulos no argumento das funções assets
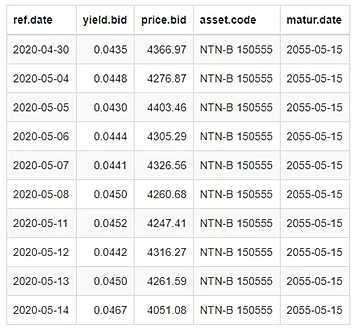
Com o comando tail(NTNB, 10) é possível conferir rapidamente os 10 últimos dados da base extraida do TD.
A base contém a data de referência (diária), o valor da taxa de compra do título, o preço de compra, o nome do título e a data de vencimento.
3. Tratando os dados para os gráficos
Introdução ao Operador Pipe (%>%)
Antes de começarmos os tratamentos dos dados, vou introduzir rapidamente o conceito do operador pipe, pois, além de ser utilizado no nosso código, ele possui vantagens na leitura de código e é amplamente utilizado na comunidade R, e você poderá se deparar com ele novamente. Para isso, eu peguei emprestado um exemplo do tutorial da curso-R que apresenta um caso simples e de rápido entendimento do uso do operador.

Em resumo, o operador pipe acumula o resultado da operação à esquerda do operador e aplica o resultado à função à direita do operador. Desta forma, é possível encadear diferentes ações que ocorrem em uma única base de dados, em uma única sequência de código altamente legível.
Voltando aos filtros e tratamentos
Como nosso objetivo é avaliar o impacto dos acontecimentos ocorridos em março/20 e abril/20 no mercado de títulos, devemos aplicar alguns filtros para prosseguirmos a análise. Iremos selecionar (i) as negociações que ocorreram no intervalo de Outubro/2019 a Maio/2020, (ii) os títulos NTN-B com pagamentos de juros semestrais para isolar a diferença de taxa entre títulos com e sem cupom e, por fim, (iii) selecionar alguns vencimentos específicos para não poluirmos a visualização e conseguirmos avaliar o impacto em diferentes maturidades.

Criamos um vetor venc_ntnbs com os vencimentos selecionados em 2020, 2024, 2035 e 2050 onde iremos filtrar vencimentos.
Em seguida, filtramos as observações cuja variável matur.date é a mesma que algum dos vencimentos selecionados no vetor venc_ntnbs. Para isso, utilizamos o operador %in% dentro da função filter. O segundo filtro seleciona observações cuja variável de negociação ref.date é menor que a data 2019-08-01. O último filtro seleciona observações que não possuem o texto “Principal” na variável asset.code.
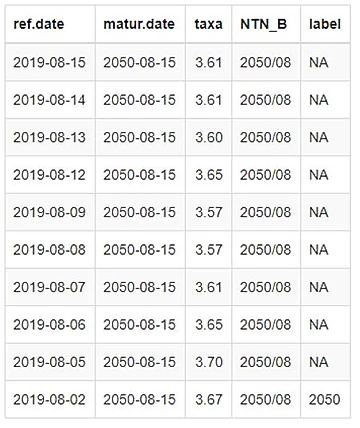
Com a função mutate podemos criar diversas variáveis de uma única vez rapidamente. Primeiro multiplicamos a coluna yield.bid por 100 para uma melhor visualização no gráfico, depois criamos a variável NTN_B contendo o ano e o mês do vencimento no formato (AAAA/MM) e por último utilizamos uma condição com a função if_else() para criar a variável label, contendo o ano do vencimento na primeira observação e contendo NA nas demais observações para criarmos o rótulo do vencimento no gráfico.
Por fim, a função arrange() ordena a tabela através das variáveis NTN_B e ref.date e retiramos as colunas yield.bid, asset.code e price.bid com a função select(). Segue abaixo o output do comando tail(NTNB, 10).
4. Construindo a Visualização
Agora entraremos na parte mais complexa do código devido ao uso de inúmeras funções distintas, com cada uma delas contendo vários argumentos. Como seria inviável explicar item por item, vou passar uma visão geral sobre quais são as funções que geram os principais elementos do nosso gráfico final, dando insumos para que você encontre as respostas de dúvidas futuras sobre o código completo nas documentações das funções. Além disso, dúvidas e/ou sugestões nos comentários também são bem vindas. =]
Inicialmente, somente estas duas linhas do pacote ggplot2 contido no pacote tidyverse são capazes de gerar nosso gráfico. Porém, apesar da visualização ser esclarecedora, ela não é nem um pouco atrativa esteticamente.
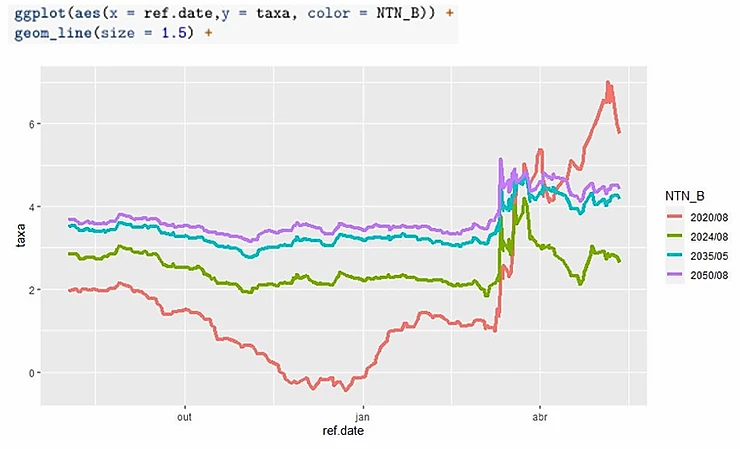
Para melhorar esteticamente nossa visualização, precisamos customizar os elementos do gráfico como um todo, ajustar nomes de eixos e títulos, adicionar créditos e fonte, substituir a legenda por rótulos dentro do gráfico com apenas o ano de vencimento e, por fim, indicar os períodos de destaque através de linhas, setas e rótulos.
Pois bem, começando com os destaques da nossa análise, utilizei a função geom_vline() para criar as linhas verticais para cada um dos dias, a função geom_label() para criar os rótulos com os textos “Corona Day” e “Moro Day” e a função geom_curve() para criar as curvas que ligam os rótulos às linhas verticais. Para todas as funções é necessário indicar, através dos argumentos, as posições dos elementos nos eixos, junto com cores e elementos específicos. Adicionalmente, utilizei a função geom_label_repel() do pacote ggrepel para criar os rótulos com o vencimento de cada título.
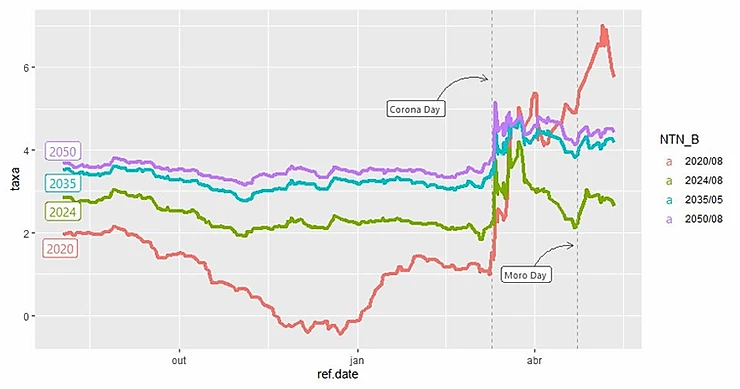
Em seguida, renomeei eixos e títulos, adicionei crédito e fonte através de funções como ggtitle(), xlab(), ylab() e caption(). Também adicionei um tema de gráfico, conforme o meu gosto pessoal utilizando o padrão theme_clean() do pacote ggthemes. Além disso, foi necessário fazer alguns ajustes internos ao tema escolhido utilizando a função theme(), como excluir a legenda que não era mais necessária e centralizar o título.
Dicas:
(i) Faça testes utilizando diferentes temas do pacote ggplot2 e também do ggthemes para você descobrir diversos temas de gráfico que podem agradar você.
(ii) Fazendo ajustes dentro da função theme() é possível customizar QUALQUER elemento do seu gráfico.
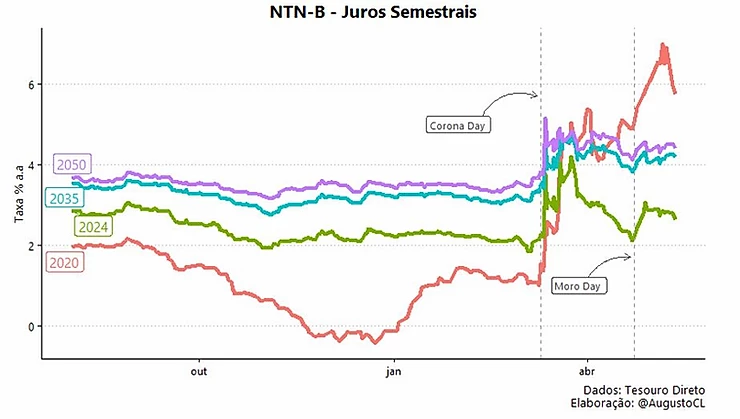
Por fim, escolhi uma paleta de cores diferente com a função scale_color_brewer() e fiz ajustes nas escalas de data e taxa com as funções scale_x_date() e scale_y_continuous(), ajustando formato de data e decimal da taxa. Após isso, utilizei a função ggsave() para adicionar as dimensões desejadas para o gráfico, resultando na nossa visualização final.
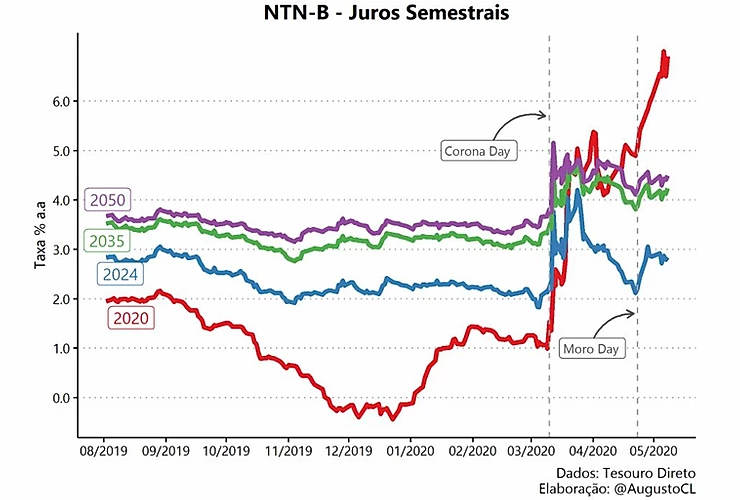
Segue abaixo o código completo para a análise:
